Back in 2008 I did a special segment in my “Secrets In Websites” series for the 2008 Presidential Elections. It was quite popular (almost crashed the server). I decided to do it again, but slightly revised for 2012.
Tag: analytics
Categories
Monkey Search Terms


Top monkeyology search terms via Google Analytics… you’re all very sick individuals.
Categories
How To Install Software In Robert
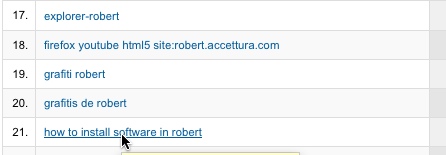
Total WTF search query in analytics: “how to install software in robert”
I was curious who is indexing the links that people tweet on Twitter. It’s obvious someone does since links get ‘clicks’ almost immediately after submission. To do this presumably they are tapping into the xmpp firehose.
Lets take a look:
66.xxx.xxx.xxx - - [06/Dec/2009:20:17:43 +0000] "GET /test HTTP/1.1" 301 20 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
I guess Google has a deal with Twitter. Googlebot indexed just a few seconds after it was sent. As far as I know nothing is actually announced. This is the first evidence I know of a potential deal of some sort. I’d be shocked if Google is scraping the site this quickly.
Edit: Stephen Duncan pointed out in the comments that this was announced in October. Totally forgot about that.
208.xxx.xxx.xxx - - [06/Dec/2009:20:17:47 +0000] "GET /test HTTP/1.0" 301 - "-" "Mozilla/5.0 (compatible; Butterfly/1.0; +http://labs.topsy.com/butterfly.html) Gecko/2009032608 Firefox/3.0.8"
This is Topsy, a twitter search engine. Never saw this site before. Few tests and I actually kind of like the output.
89.xxx.xxx.xxx - - [06/Dec/2009:20:17:58 +0000] "GET /test HTTP/1.1" 301 - "-" "Mozilla/5.0 (compatible; MSIE 6.0b; Windows NT 5.0) Gecko/2009011913 Firefox/3.0.6 TweetmemeBot"
Tweetmeme mines Twitter links and attempts to build a Digg-like index based on retweets rather than Diggs.
75.xxx.xxx.xxx - - [06/Dec/2009:20:18:05 +0000] "GET /test HTTP/1.1" 301 - "-" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)" 72.xxx.xxx.xxx - - [06/Dec/2009:20:20:25 +0000] "GET /test HTTP/1.1" 301 - "-" "Python-urllib/2.5"
Can’t identify these AWS hosted services.
70.xxx.xxx.xxx - - [06/Dec/2009:20:20:53 +0000] "GET /test HTTP/1.1" 301 20 "-" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)" 70.xxx.xxx.xxx - - [06/Dec/2009:20:24:23 +0000] "GET /test HTTP/1.1" 301 20 "-" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"
This is actually Microsoft. Microsoft’s Bing search engine indexes Twitter. I’m not sure why they indexed twice in such close intervals that seems odd for this day and age.
Mining logs a little deeper it looks like when tweets meet certain criteria (such as retweeted) there are other bots that spider them. It also looks like other search engines may be indexing at a slower rate (Baidu for example).
There are several others from AWS and a few other dedicated providers. These servers are obviously trying to keep a low profile, they don’t even have reverse DNS.
So there you go. Just a matter of seconds after a link hits Twitter this all happens.
Here’s a few more from another Tweet that weren’t in the first set:
Edit: More!:
75.xxx.xxx.xxx - - [06/Dec/2009:20:49:42 +0000] "GET /test HTTP/1.1" 301 - "-" "Mozilla/5.0 (compatible; Feedtrace-bot/0.2; bot@feedtrace.com)"
Feedtrace is some sort of twitter mining service currently in beta.
67.xxx.xxx.xxx - - [06/Dec/2009:20:49:45 +0000] "GET /test HTTP/1.0" 301 - "-" "Mozilla/5.0 (compatible; mxbot/1.0; +http://www.chainn.com/mxbot.html)"
Chainn is a social data mining service with a few apps that make use of the data it collects.
Categories
Yahoo! Web Analytics
It went somewhat unnoticed, but Yahoo! today announced it’s Yahoo! Web Analytics package which is intended to compete with the wildly popular Google Analytics. I’ve spent quite a few hours in analytics packages over the years ranging from very amateurish to enterprise grade. Google Analytics is a very good product but it does have limitations. The biggest limitation is the lack of real-time reporting. Google Analytics takes a few hours, making it for most people next-day service. This isn’t a big deal for some, but if your in an environment where you need feedback on your content ASAP (a must for media sites), this is a huge deal. Yahoo is promising to deliver “within minutes”:
Get detailed reporting within minutes after an action occurs on your website. Quickly identify dips in key site metrics or monitor the performance of new content. Seeing the impact of website and marketing changes immediately makes it much easier to optimize them. Yahoo! Web Analytics also maintains historical data so you can go back at any time to review old data for new insight, or compare the present to the past without any changes to your page tags.
Interesting. I wonder if this will light a fire under Google’s butt to deliver real-time analytics as well. Urchin wasn’t really designed for real-time data. Google’s obviously done a lot of work with it to build Google Analytics. I wonder if that’s the next step for them.
Categories
Secrets In Websites II
This post is a follow up to the first Secrets In Websites. For those who don’t remember the first time, I point out odd, interesting, funny things in other websites’ code. Yes it takes some time to put a post like this together, that’s why it’s just about a year since the last time. Enough with the intro, read on for the code.
Categories
Tab Impact On Total Time Spent
As everyone in the industry knows, Nielsen/NetRatings no longer relies on page views instead preferring total time spent. This makes sense since ajax applications can have 1 page view, but keep a user for an hour. Not to mention other things like video or Flash. The use of time spent is likely much more accurate. In my mind “time spent” is time actually spent on the site (I’m a literal guy).
This of course raises an interesting question. How do tabs influence this metric? Take the following situation as an example. A user visits a home page, and opens a link in a new tab. Then finds another link and opens it in a new [background] tab. That’s 3 tabs in 1 visit (assume visit to be 30 minutes).
Before tabs, most browser sessions would look like this:

There’s now an increasing number that will look like this (gray is a tab not in view):
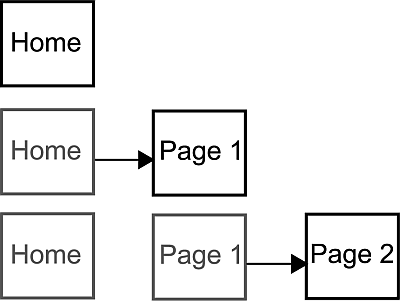
If we assume total time on the site is time between the first and last page, we potentially undercount the total time on sites that list information (for example Digg). The total time to make those clicks could be < 10 seconds, but the time spent reading those two page alone might be > 10 minutes. Many tab power-users from what I’ve read around the web over the years essentially use them as a way to bookmark their “to read” list (including myself). It also undercounts sites like Gmail which are ajax based (1 page) but can be used for several minutes.
If we use javascript to “ping” (call back by placing a tracker gif) the analytics service every x seconds to see if the page is still open, we potentially double count since a user can’t be in 3 tabs at once. The clock would be counting 3 seconds for every 1 second the user is actually looking at the page.
This raises the question: are sites that are heavily used by Firefox, Safari, Opera and IE7 site underestimated or overestimated because of the way users browse the site? How do you accurately tell how long a view is when a user can have multiple tabs?
Another example is someone who keeps their webmail open in a tab all afternoon for easy access. They may only check it 1x measuring no more than 1 minute in actual attention. But it’s open for 5 hrs. What is the real time on the page? You can measure my interaction (opening/closing mail). But what if I’m reading an email for an hour (it’s a really complicated one)? How does that compare to just leaving it open in the background?
This is really no different than using new windows, the difference being that most people seem to have found windows to be annoyance, while tabs are a “feature”. The increase in usage and popularity in a time where visit length matters raises an interesting question. How do you measure it?
One assumption is that it’s just a small percentage of the population, which is likely true. The problem with this assumption is that it’s one subject to change as the browserscape matures and users learn about new features. Another assumption is to just account for all time a page is open, even if it’s not visible. The downside I see here is that it’s pretty inaccurate. As a content producer I’d like to know if my content is used, or just loaded on a users computer. If I were an advertiser I’d care even more.
I’m not sure how analytics firms approach this. In a sense it’s similar to the “hotel problem“. Perhaps just something you need to decide upon and live with.